[2]:
import networkx as nx
from matplotlib import pyplot as plt
import numpy as np
import networkx as nx
import torch
from gsnn.models.GSNN import GSNN
from gsnn.simulate.nx2pyg import nx2pyg
from gsnn.simulate.simulate import simulate, simulate_sde
from gsnn.interpret.extract_entity_function import extract_entity_function
%load_ext autoreload
%autoreload 2
# for reproducibility
torch.manual_seed(0)
np.random.seed(0)
Simulating structured data
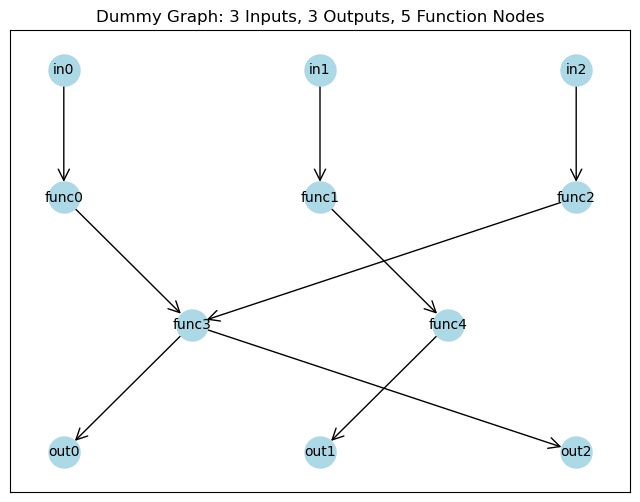
To demonstrate how the GSNN operates, and some simple capabilities, we have written a simple bayesian network simulator. We will start by defining a simple toy graph with three inputs and three outputs.
[3]:
# Create a simple directed graph with 3 inputs, 3 outputs, and 5 function nodes
G = nx.DiGraph()
# Add input nodes, function nodes, and output nodes
input_nodes = ['in0', 'in1', 'in2']
function_nodes = ['func0', 'func1', 'func2', 'func3', 'func4']
output_nodes = ['out0', 'out1', 'out2']
# Add edges from input nodes to function nodes
G.add_edges_from([('in0', 'func0'), ('in1', 'func1'), ('in2', 'func2')])
# Add edges between function nodes
G.add_edges_from([('func0', 'func3'), ('func1', 'func4'), ('func2', 'func3')])
# Add edges from function nodes to output nodes
G.add_edges_from([('func3', 'out0'), ('func4', 'out1'), ('func3', 'out2')])
# Define positions for each node for plotting
pos = {
'in0': (-2, 2), 'in1': (0, 2), 'in2': (2, 2),
'func0': (-2, 1), 'func1': (0, 1), 'func2': (2, 1),
'func3': (-1, 0), 'func4': (1, 0),
'out0': (-2, -1), 'out1': (0, -1), 'out2': (2, -1)
}
# Plot the graph
plt.figure(figsize=(8, 6))
nx.draw_networkx(G, pos, with_labels=True, node_color='lightblue', node_size=500, font_size=10, arrowstyle='->', arrowsize=20)
plt.title("Dummy Graph: 3 Inputs, 3 Outputs, 5 Function Nodes")
plt.show()
Simulating function nodes
To simulate more complex functions, we can add specific function behaviors to our network by passing the special_functions dict to simulate. This enables us to add non-linear node functions to the graph. For instance, in the example below, func2 will exponentiate the inputs.
The simulate function uses pyro to create a bayesian network that emualtes our graph structure. For our application, each node is modeled as a univariate standard normal distribution where the scale and location of each node is dependant on the values of the preceding nodes.
NOTE: Using bayesian networks requires that no cycles exists in the graph. Notably, the GSNN can handle cycles and we plan to add more complex simulations that can create these behaviors (i.e., ODE simulations)
[4]:
special_functions = {'func1': lambda x: -np.mean(x), 'func2':lambda x: np.sum([np.exp(xx) for xx in x]),
'func0': lambda x: np.mean(([(xx)**2 for xx in x])), 'func3': lambda x: -np.mean(x) if all([xx > 0 for xx in x]) else np.mean(x)}
x_train, x_test, y_train, y_test = simulate(G, n_train=500, n_test=100, input_nodes=input_nodes, output_nodes=output_nodes,
special_functions=special_functions, noise_scale=0.001)
device = 'cuda' if torch.cuda.is_available() else 'cpu'
x_train = torch.tensor(x_train, dtype=torch.float32).to(device)
y_train = torch.tensor(y_train, dtype=torch.float32).to(device)
x_test = torch.tensor(x_test, dtype=torch.float32).to(device)
y_test = torch.tensor(y_test, dtype=torch.float32).to(device)
Training GSNN with simulated data
We can train a GSNN model using our synthetic data. Note that we have chosen the hyperparameters to demonstrate some of the inner workings of the GSNN, however, changing these hyperparameters can muddy the interpretation.
[9]:
data = nx2pyg(G, input_nodes, function_nodes, output_nodes)
model = GSNN(data.edge_index_dict,
data.node_names_dict,
channels=20,
layers=2,
share_layers=False,
bias=True,
add_function_self_edges=False,
checkpoint=False,
norm='none',
init='degree_normalized',
residual=True,
node_attn=False,
node_mlp=False,
dropout=0.).to(device)
print('n params', sum([p.numel() for p in model.parameters()]))
optim = torch.optim.AdamW(model.parameters(), lr=1e-2, weight_decay=1e-2)
crit = torch.nn.MSELoss()
losses_gsnn = []
for i in range(1000):
model.train()
optim.zero_grad()
yhat = model(x_train)
loss = crit(y_train, yhat)
loss.backward()
optim.step()
with torch.no_grad():
model.eval()
yhat = model(x_test)
loss = crit(y_test, yhat)
print(f'iter: {i} | loss: {loss.item():.3f}',end='\r')
n params 700
iter: 999 | loss: 0.118
Interpreting learned functions
We can also extract individual function nodes and evaluate their learned behavior. Note that function nodes that have more than one input or output will require more advanced visualization or interpretation methods (SHAP, LIME, etc.)
Interpretation limitations
In most scenarios, we do not know the exact required path length and will want to use more competive architectures that make interpretation of individual function nodes more complicated. For instance, if we use a greater number of layers, then many layers may contribute to the prediction of an outcome, so the true effect a function node is an aggregate of many layers behaviors. This challenge is further exacerbated if we change share_layers=False as each layer will learn unique functions for
each node.
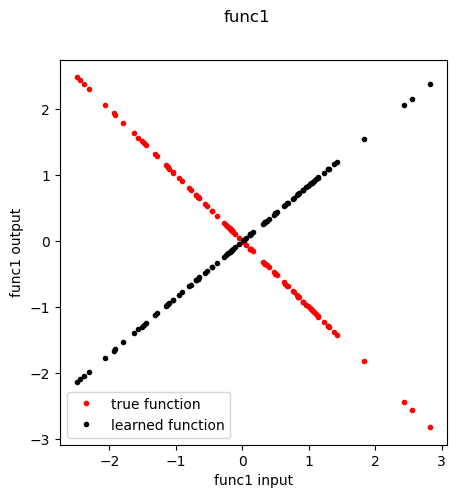
Additionally, in a “chain” of latent functions, the specific functions may be shuffled or aggregated, and the sign of individual function nodes may be flipped. For instance, in our example func1 and func4 may be switched but would still have good performance. In more complex networks with a greater number of outputs, this behavior is liable to converge to more accurate function specific representations.
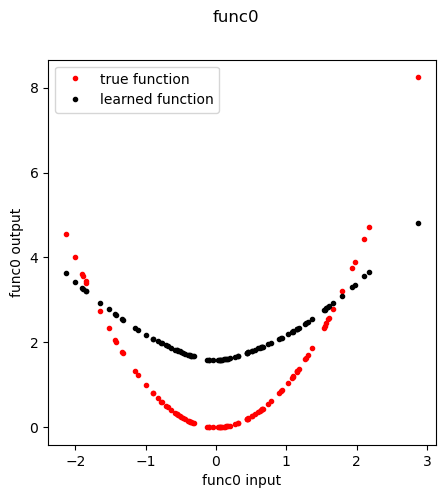
Extract the Func0 GSNN learned node function
[10]:
model = model.eval()
[11]:
fn = 'func0'
f,axes = plt.subplots(1,1, figsize=(5,5), sharey=True)
plt.suptitle( fn )
func, meta = extract_entity_function(node=fn, model=model, data=data, layer=0)
n_inputs = func.lin_in.weight.data.shape[1]
inp = torch.randn(100, n_inputs)
out = func(inp)
if fn in special_functions:
out_true = [special_functions[fn](np.array(x)) for x in inp]
else:
out_true = [x for x in inp]
plt.plot(inp, out_true, 'r.', label='true function')
plt.plot(inp.detach().cpu().numpy().ravel(), out.detach().cpu().numpy().ravel(), 'k.', label='learned function')
plt.xlabel(f'{fn} input')
plt.ylabel(f'{fn} output')
plt.legend()
plt.show()
[12]:
fn = 'func1'
f,axes = plt.subplots(1,1, figsize=(5,5), sharey=True)
plt.suptitle( fn )
func, meta = extract_entity_function(node=fn, model=model, data=data, layer=0)
n_inputs = func.lin_in.weight.data.shape[1]
inp = torch.randn(100, n_inputs)
out = func(inp)
if fn in special_functions:
out_true = [special_functions[fn](np.array(x)) for x in inp]
else:
out_true = [x for x in inp]
plt.plot(inp, out_true, 'r.', label='true function')
plt.plot(inp.detach().cpu().numpy().ravel(), out.detach().cpu().numpy().ravel(), 'k.', label='learned function')
plt.xlabel(f'{fn} input')
plt.ylabel(f'{fn} output')
plt.legend()
plt.show()
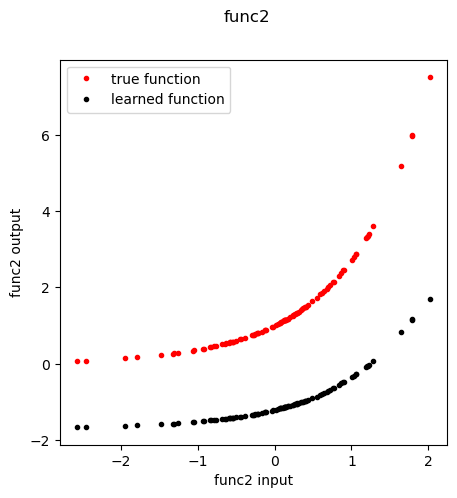
Extract the Func2 GSNN learned node function
[ ]:
fn = 'func2'
f,axes = plt.subplots(1,1, figsize=(5,5), sharey=True)
plt.suptitle( fn )
func, meta = extract_entity_function(node=fn, model=model, data=data, layer=0)
n_inputs = func.lin_in.weight.data.shape[1]
inp = torch.randn(100, n_inputs)
out = func(inp)
if fn in special_functions:
out_true = [special_functions[fn](np.array(x)) for x in inp]
else:
out_true = [x for x in inp]
plt.plot(inp, out_true, 'r.', label='true function')
plt.plot(inp.detach().cpu().numpy().ravel(), out.detach().cpu().numpy().ravel(), 'k.', label='learned function')
plt.xlabel(f'{fn} input')
plt.ylabel(f'{fn} output')
plt.legend()
plt.show()
/tmp/ipykernel_4829/417286389.py:12: DeprecationWarning: __array__ implementation doesn't accept a copy keyword, so passing copy=False failed. __array__ must implement 'dtype' and 'copy' keyword arguments. To learn more, see the migration guide https://numpy.org/devdocs/numpy_2_0_migration_guide.html#adapting-to-changes-in-the-copy-keyword
out_true = [special_functions[fn](np.array(x)) for x in inp]
simulating data with stochastic differential equations
[8]:
x_train, y_train, x_test, y_test = simulate_sde(
G, n_train=500, n_test=200,
input_nodes=input_nodes,
output_nodes=output_nodes,
noise_scale=0.5, # Diffusion coefficient
dt=0.01, # Time step for integration
t_final=10.0, # Final integration time
special_functions=special_functions,
seed=42 # For reproducibility
)
---------------------------------------------------------------------------
KeyboardInterrupt Traceback (most recent call last)
Cell In[8], line 1
----> 1 x_train, y_train, x_test, y_test = simulate_sde(
2 G, n_train=500, n_test=200,
3 input_nodes=input_nodes,
4 output_nodes=output_nodes,
File /home/exacloud/gscratch/mcweeney_lab/evans/GSNN/gsnn/simulate/simulate.py:253, in simulate_sde(G, n_train, n_test, input_nodes, output_nodes, noise_scale, dt, t_final, special_functions, seed, signed_edges)
250 return np.array(x_samples), np.array(y_samples)
252 # Generate training and test samples
--> 253 x_train, y_train = generate_samples(n_train)
254 x_test, y_test = generate_samples(n_test)
256 return x_train, y_train, x_test, y_test
File /home/exacloud/gscratch/mcweeney_lab/evans/GSNN/gsnn/simulate/simulate.py:245, in simulate_sde.<locals>.generate_samples(n_samples)
242 x_values = np.random.normal(0, 1, len(input_nodes))
244 # Solve the stochastic ODE system
--> 245 y_values = solve_sde(x_values, n_steps)
247 x_samples.append(x_values)
248 y_samples.append(y_values)
File /home/exacloud/gscratch/mcweeney_lab/evans/GSNN/gsnn/simulate/simulate.py:224, in simulate_sde.<locals>.solve_sde(input_values, n_steps)
222 # Integrate over time
223 for _ in range(n_steps):
--> 224 y = euler_maruyama_step(y, dt, noise_scale)
226 # Extract output values
227 output_values = []
File /home/exacloud/gscratch/mcweeney_lab/evans/GSNN/gsnn/simulate/simulate.py:200, in simulate_sde.<locals>.euler_maruyama_step(y, dt, noise_scale)
196 def euler_maruyama_step(y, dt, noise_scale):
197 """
198 Perform one step of Euler-Maruyama integration.
199 """
--> 200 drift = sde_system(0, y, noise_scale) # t not used in our system
201 noise = np.random.normal(0, np.sqrt(dt) * noise_scale, size=y.shape)
203 # Input nodes don't get noise
File /home/exacloud/gscratch/mcweeney_lab/evans/GSNN/gsnn/simulate/simulate.py:183, in simulate_sde.<locals>.sde_system(t, y, noise_scale)
181 # Apply special function if available
182 if special_functions and node in special_functions:
--> 183 parent_sum = special_functions[node](parent_values)
184 else:
185 # Default: weighted sum of parents
186 for parent in parents:
Cell In[4], line 1, in <lambda>(x)
----> 1 special_functions = {'func1': lambda x: -np.mean(x), 'func2':lambda x: np.sum([np.exp(xx) for xx in x]),
2 'func0': lambda x: np.mean(([(xx)**2 for xx in x])), 'func3': lambda x: -np.mean(x) if all([xx > 0 for xx in x]) else np.mean(x)}
File /home/exacloud/gscratch/mcweeney_lab/evans/external/miniforge3/envs/gsnn/lib/python3.11/site-packages/numpy/core/fromnumeric.py:3504, in mean(a, axis, dtype, out, keepdims, where)
3501 else:
3502 return mean(axis=axis, dtype=dtype, out=out, **kwargs)
-> 3504 return _methods._mean(a, axis=axis, dtype=dtype,
3505 out=out, **kwargs)
File /home/exacloud/gscratch/mcweeney_lab/evans/external/miniforge3/envs/gsnn/lib/python3.11/site-packages/numpy/core/_methods.py:118, in _mean(a, axis, dtype, out, keepdims, where)
115 dtype = mu.dtype('f4')
116 is_float16_result = True
--> 118 ret = umr_sum(arr, axis, dtype, out, keepdims, where=where)
119 if isinstance(ret, mu.ndarray):
120 with _no_nep50_warning():
KeyboardInterrupt:
[ ]:
device = 'cuda' if torch.cuda.is_available() else 'cpu'
x_train = torch.tensor(x_train, dtype=torch.float32).to(device)
y_train = torch.tensor(y_train, dtype=torch.float32).to(device)
x_test = torch.tensor(x_test, dtype=torch.float32).to(device)
y_test = torch.tensor(y_test, dtype=torch.float32).to(device)
[ ]:
data = nx2pyg(G, input_nodes, function_nodes, output_nodes)
model = GSNN(data.edge_index_dict,
data.node_names_dict,
channels=30,
layers=2,
share_layers=False,
bias=True,
add_function_self_edges=False,
checkpoint=False,
norm='none',
init='degree_normalized',
residual=True,
node_attn=False,
dropout=0.0).to(device)
print('n params', sum([p.numel() for p in model.parameters()]))
optim = torch.optim.AdamW(model.parameters(), lr=1e-3, weight_decay=1e-4)
crit = torch.nn.MSELoss()
losses_gsnn = []
for i in range(1000):
model.train()
optim.zero_grad()
yhat = model(x_train)
loss = crit(y_train, yhat)
loss.backward()
optim.step()
with torch.no_grad():
model.eval()
yhat = model(x_test)
loss = crit(y_test, yhat)
print(f'iter: {i} | loss: {loss.item():.3f}',end='\r')
n params 17348
iter: 999 | loss: 0.673
[ ]:
np.corrcoef(yhat.detach().cpu().numpy().ravel(), y_test.detach().cpu().numpy().ravel())[0,1]
np.float64(0.8916956887319947)
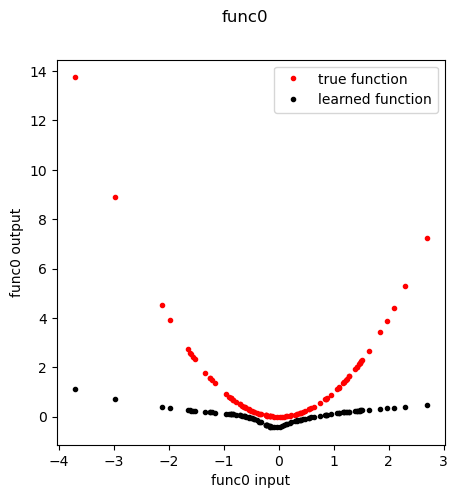
[ ]:
fn = 'func0'
f,axes = plt.subplots(1,1, figsize=(5,5), sharey=True)
plt.suptitle( fn )
func, meta = extract_entity_function(node=fn, model=model, data=data, layer=0)
n_inputs = func.lin_in.weight.data.shape[1]
inp = torch.randn(100, n_inputs)
out = func(inp)
if fn in special_functions:
out_true = [special_functions[fn](np.array(x)) for x in inp]
else:
out_true = [x for x in inp]
plt.plot(inp, out_true, 'r.', label='true function')
plt.plot(inp.detach().cpu().numpy().ravel(), out.detach().cpu().numpy().ravel(), 'k.', label='learned function')
plt.xlabel(f'{fn} input')
plt.ylabel(f'{fn} output')
plt.legend()
plt.show()
/tmp/ipykernel_4829/1489212564.py:12: DeprecationWarning: __array__ implementation doesn't accept a copy keyword, so passing copy=False failed. __array__ must implement 'dtype' and 'copy' keyword arguments. To learn more, see the migration guide https://numpy.org/devdocs/numpy_2_0_migration_guide.html#adapting-to-changes-in-the-copy-keyword
out_true = [special_functions[fn](np.array(x)) for x in inp]
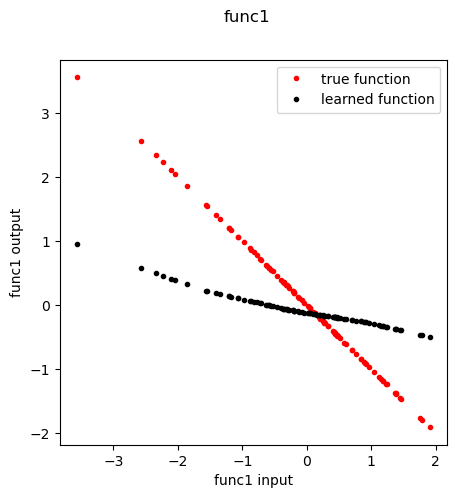
[ ]:
fn = 'func1'
f,axes = plt.subplots(1,1, figsize=(5,5), sharey=True)
plt.suptitle( fn )
func, meta = extract_entity_function(node=fn, model=model, data=data, layer=0)
n_inputs = func.lin_in.weight.data.shape[1]
inp = torch.randn(100, n_inputs)
out = func(inp)
if fn in special_functions:
out_true = [special_functions[fn](np.array(x)) for x in inp]
else:
out_true = [x for x in inp]
plt.plot(inp, out_true, 'r.', label='true function')
plt.plot(inp.detach().cpu().numpy().ravel(), out.detach().cpu().numpy().ravel(), 'k.', label='learned function')
plt.xlabel(f'{fn} input')
plt.ylabel(f'{fn} output')
plt.legend()
plt.show()
/tmp/ipykernel_4829/591615005.py:12: DeprecationWarning: __array__ implementation doesn't accept a copy keyword, so passing copy=False failed. __array__ must implement 'dtype' and 'copy' keyword arguments. To learn more, see the migration guide https://numpy.org/devdocs/numpy_2_0_migration_guide.html#adapting-to-changes-in-the-copy-keyword
out_true = [special_functions[fn](np.array(x)) for x in inp]
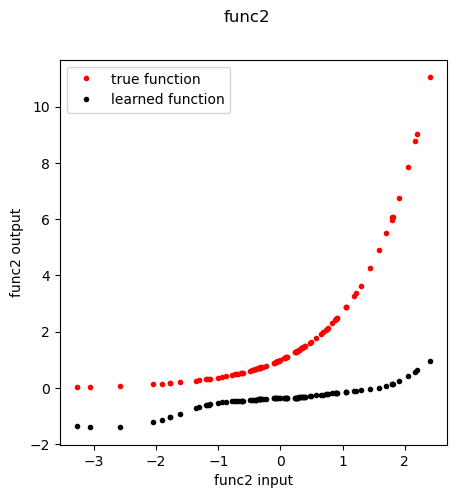
[ ]:
fn = 'func2'
f,axes = plt.subplots(1,1, figsize=(5,5), sharey=True)
plt.suptitle( fn )
func, meta = extract_entity_function(node=fn, model=model, data=data, layer=0)
n_inputs = func.lin_in.weight.data.shape[1]
inp = torch.randn(100, n_inputs)
out = func(inp)
if fn in special_functions:
out_true = [special_functions[fn](np.array(x)) for x in inp]
else:
out_true = [x for x in inp]
plt.plot(inp, out_true, 'r.', label='true function')
plt.plot(inp.detach().cpu().numpy().ravel(), out.detach().cpu().numpy().ravel(), 'k.', label='learned function')
plt.xlabel(f'{fn} input')
plt.ylabel(f'{fn} output')
plt.legend()
plt.show()
/tmp/ipykernel_4829/417286389.py:12: DeprecationWarning: __array__ implementation doesn't accept a copy keyword, so passing copy=False failed. __array__ must implement 'dtype' and 'copy' keyword arguments. To learn more, see the migration guide https://numpy.org/devdocs/numpy_2_0_migration_guide.html#adapting-to-changes-in-the-copy-keyword
out_true = [special_functions[fn](np.array(x)) for x in inp]
[ ]:
[ ]:
[ ]: