[1]:
import networkx as nx
from matplotlib import pyplot as plt
import numpy as np
from scipy.integrate import solve_ivp
import networkx as nx
import torch
import copy
from torch.distributions.bernoulli import Bernoulli
import pandas as pd
from gsnn.models.GSNN import GSNN
from gsnn.models.NN import NN
from gsnn.simulate.nx2pyg import nx2pyg
from gsnn.simulate.datasets import simulate_3_in_3_out
from gsnn.optim.Environment import Environment
from gsnn.optim.RewardScaler import RewardScaler
from gsnn.models.GSNN import GSNN
from sklearn.metrics import roc_auc_score
from gsnn.optim.REINFORCE import REINFORCE
import argparse
from sklearn.metrics import confusion_matrix
import seaborn as sbn
# for reproducibility
torch.manual_seed(0)
np.random.seed(0)
%load_ext autoreload
%autoreload 2
/home/teddy/miniconda3/envs/gsnn-mds/lib/python3.12/site-packages/tqdm/auto.py:21: TqdmWarning: IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.html
from .autonotebook import tqdm as notebook_tqdm
Reinforcement learning for structure optimization
In many cases, prior knowledge is incomplete, noisy or spurrious for specific prediction tasks. In this example, we will demonstrate how we can use the reinforcement learning for the optimal selection of prior knowledge.
NOTE: This procedure requires running many sequential training loops, and therefore is not applicable to large graphs or large datasets (where training time is significant). That said, RL’s ability to identify true edges does offer a convenient evaluation of our premise that the true graph structure should result in better performances than alternative graph structures.
Additionally, I’ve found that the “auc” (sum of all epoch test scores) reward type seens to be more resilient than “best” or “last”, which may suggest that the true graph has advantages in early training, but less so in terms of late training or best test performance.
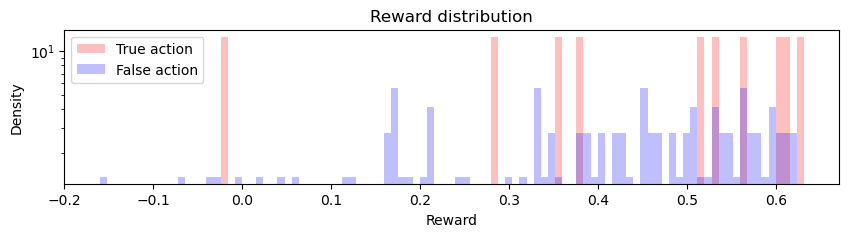
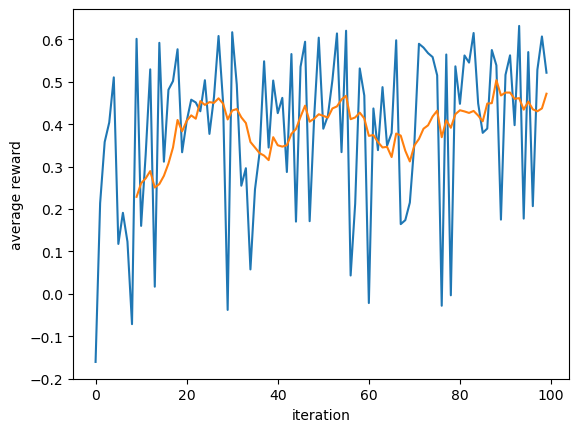
It is also worth noting that the rewards are farily noisy (same action can result in a varied rewards), which may account for why the “best_action” is not always the true action (graph), whereas the policy is often a more robust metric of the true action.
[2]:
G, pos, x_train, x_test, y_train, y_test, \
input_nodes, function_nodes, output_nodes = simulate_3_in_3_out(n_train=100, n_test=500,
noise_scale=0.5, zscorey=True)
plt.figure(figsize=(8, 6))
nx.draw_networkx(G, pos, with_labels=True, node_color='lightblue', node_size=500, font_size=10, arrowstyle='->', arrowsize=20)
plt.title("Dummy Graph: 3 Inputs, 3 Outputs, 5 Function Nodes")
plt.show()
[3]:
data = nx2pyg(G, input_nodes, function_nodes, output_nodes)
# add some false edges
edge_index_dict = copy.deepcopy(data.edge_index_dict)
# add some false input edges
edge_index_dict['input', 'to', 'function'] = torch.cat((edge_index_dict['input', 'to', 'function'],
torch.tensor([[0, 1, 2, 1],
[1, 0, 1, 2]],
dtype=torch.long)), dim=-1)
[4]:
input_edges = set([(i.item(),j.item()) for i,j in data.edge_index_dict['input', 'to', 'function'].T])
action_label_dict = {}
action_label_dict[('input', 'to', 'function')] = [(i.item(), j.item()) in input_edges for i,j in edge_index_dict['input', 'to', 'function'].T]
true_action = 1.*np.array(action_label_dict[('input', 'to', 'function')])
[5]:
device = 'cuda' if torch.cuda.is_available() else 'cpu'
train_dataset = torch.utils.data.TensorDataset(x_train, y_train)
test_dataset = torch.utils.data.TensorDataset(x_test, y_test)
[6]:
# GSNN model parameters
model_kwargs = {'edge_index_dict' : edge_index_dict,
'node_names_dict' : data.node_names_dict,
'channels' : 5,
'layers' : 5,
'dropout' : 0.0,
'init' : 'degree_normalized',
'residual' : True,
'share_layers' : False,
'node_attn' : False,
'add_function_self_edges' : True,
'norm' : 'layer',
'norm_first' : True,
'node_mlp_hidden' : 64}
# GSNN training parameters
training_kwargs = {'lr':1e-2,
'max_epochs':50,
'batch':250,
'workers':1,
'weight_decay':1e-4}
# the action edge dict will be used to index the action for each edge
# if and edge key is not provided, those values will not be optimized (always present)
action_edge_dict = {('input', 'to', 'function'): torch.arange(edge_index_dict['input', 'to', 'function'].shape[1])}
n_actions = sum([torch.unique(v).numel() for v in action_edge_dict.values()])
env = Environment(action_edge_dict, train_dataset, test_dataset, model_kwargs,
training_kwargs, metric='spearman', reward_type='best', verbose=False,
raise_error_on_fail=True)
hoptim = REINFORCE(env, n_actions, action_labels=true_action, clip=10, eps=1e-8, warmup=3, verbose=True,
entropy=0., entropy_decay=0.99, min_entropy=0.0, window=10,
init_prob=0.5, lr=1e-1, policy_decay=0.)
for iter in range(100):
hoptim.step()
--> iter: 1 || auroc 0.500 || acc: 0.571 || prob(true_action): 7.812E-03 || last reward: -0.160
--> iter: 2 || auroc 0.500 || acc: 0.571 || prob(true_action): 7.812E-03 || last reward: 0.214
--> iter: 3 || auroc 0.500 || acc: 0.571 || prob(true_action): 7.812E-03 || last reward: 0.358
--> iter: 4 || auroc 0.583 || acc: 0.571 || prob(true_action): 8.142E-03 || last reward: 0.404
--> iter: 5 || auroc 0.750 || acc: 0.571 || prob(true_action): 9.008E-03 || last reward: 0.510
--> iter: 6 || auroc 0.750 || acc: 0.571 || prob(true_action): 9.388E-03 || last reward: 0.118
--> iter: 7 || auroc 0.750 || acc: 0.571 || prob(true_action): 9.655E-03 || last reward: 0.191
--> iter: 8 || auroc 0.833 || acc: 0.714 || prob(true_action): 1.007E-02 || last reward: 0.123
--> iter: 9 || auroc 0.833 || acc: 0.571 || prob(true_action): 1.076E-02 || last reward: -0.071
--> iter: 10 || auroc 0.917 || acc: 0.571 || prob(true_action): 1.205E-02 || last reward: 0.601
--> iter: 11 || auroc 1.000 || acc: 0.571 || prob(true_action): 1.315E-02 || last reward: 0.160
--> iter: 12 || auroc 1.000 || acc: 0.571 || prob(true_action): 1.425E-02 || last reward: 0.329
--> iter: 13 || auroc 1.000 || acc: 0.571 || prob(true_action): 1.544E-02 || last reward: 0.529
--> iter: 14 || auroc 1.000 || acc: 0.571 || prob(true_action): 1.654E-02 || last reward: 0.017
--> iter: 15 || auroc 1.000 || acc: 0.571 || prob(true_action): 1.813E-02 || last reward: 0.592
--> iter: 16 || auroc 1.000 || acc: 0.714 || prob(true_action): 1.971E-02 || last reward: 0.312
--> iter: 17 || auroc 1.000 || acc: 0.714 || prob(true_action): 2.135E-02 || last reward: 0.481
--> iter: 18 || auroc 1.000 || acc: 0.714 || prob(true_action): 2.260E-02 || last reward: 0.502
--> iter: 19 || auroc 1.000 || acc: 0.714 || prob(true_action): 2.394E-02 || last reward: 0.577
--> iter: 20 || auroc 1.000 || acc: 0.714 || prob(true_action): 2.515E-02 || last reward: 0.334
--> iter: 21 || auroc 1.000 || acc: 0.714 || prob(true_action): 2.629E-02 || last reward: 0.407
--> iter: 22 || auroc 1.000 || acc: 0.714 || prob(true_action): 2.729E-02 || last reward: 0.458
--> iter: 23 || auroc 1.000 || acc: 0.714 || prob(true_action): 2.812E-02 || last reward: 0.451
--> iter: 24 || auroc 1.000 || acc: 0.714 || prob(true_action): 2.891E-02 || last reward: 0.431
--> iter: 25 || auroc 1.000 || acc: 0.714 || prob(true_action): 2.974E-02 || last reward: 0.504
--> iter: 26 || auroc 1.000 || acc: 0.714 || prob(true_action): 3.061E-02 || last reward: 0.377
--> iter: 27 || auroc 1.000 || acc: 0.714 || prob(true_action): 3.132E-02 || last reward: 0.464
--> iter: 28 || auroc 1.000 || acc: 0.857 || prob(true_action): 3.380E-02 || last reward: 0.608
--> iter: 29 || auroc 1.000 || acc: 0.857 || prob(true_action): 3.611E-02 || last reward: 0.451
--> iter: 30 || auroc 1.000 || acc: 0.857 || prob(true_action): 4.065E-02 || last reward: -0.038
--> iter: 31 || auroc 1.000 || acc: 0.857 || prob(true_action): 4.517E-02 || last reward: 0.617
--> iter: 32 || auroc 1.000 || acc: 1.000 || prob(true_action): 4.966E-02 || last reward: 0.494
--> iter: 33 || auroc 1.000 || acc: 1.000 || prob(true_action): 5.369E-02 || last reward: 0.255
--> iter: 34 || auroc 1.000 || acc: 1.000 || prob(true_action): 5.751E-02 || last reward: 0.296
--> iter: 35 || auroc 1.000 || acc: 1.000 || prob(true_action): 6.090E-02 || last reward: 0.058
--> iter: 36 || auroc 1.000 || acc: 1.000 || prob(true_action): 6.403E-02 || last reward: 0.246
--> iter: 37 || auroc 1.000 || acc: 1.000 || prob(true_action): 6.695E-02 || last reward: 0.332
--> iter: 38 || auroc 1.000 || acc: 1.000 || prob(true_action): 6.914E-02 || last reward: 0.548
--> iter: 39 || auroc 1.000 || acc: 1.000 || prob(true_action): 7.113E-02 || last reward: 0.345
--> iter: 40 || auroc 1.000 || acc: 1.000 || prob(true_action): 7.259E-02 || last reward: 0.503
--> iter: 41 || auroc 1.000 || acc: 1.000 || prob(true_action): 7.393E-02 || last reward: 0.426
--> iter: 42 || auroc 1.000 || acc: 1.000 || prob(true_action): 7.548E-02 || last reward: 0.462
--> iter: 43 || auroc 1.000 || acc: 1.000 || prob(true_action): 7.653E-02 || last reward: 0.287
--> iter: 44 || auroc 1.000 || acc: 1.000 || prob(true_action): 7.771E-02 || last reward: 0.565
--> iter: 45 || auroc 1.000 || acc: 1.000 || prob(true_action): 7.831E-02 || last reward: 0.170
--> iter: 46 || auroc 1.000 || acc: 1.000 || prob(true_action): 7.899E-02 || last reward: 0.535
--> iter: 47 || auroc 1.000 || acc: 1.000 || prob(true_action): 7.942E-02 || last reward: 0.594
--> iter: 48 || auroc 1.000 || acc: 1.000 || prob(true_action): 8.143E-02 || last reward: 0.171
--> iter: 49 || auroc 1.000 || acc: 1.000 || prob(true_action): 8.328E-02 || last reward: 0.418
--> iter: 50 || auroc 1.000 || acc: 1.000 || prob(true_action): 8.607E-02 || last reward: 0.604
--> iter: 51 || auroc 1.000 || acc: 1.000 || prob(true_action): 8.858E-02 || last reward: 0.389
--> iter: 52 || auroc 1.000 || acc: 1.000 || prob(true_action): 9.090E-02 || last reward: 0.420
--> iter: 53 || auroc 1.000 || acc: 1.000 || prob(true_action): 9.291E-02 || last reward: 0.504
--> iter: 54 || auroc 1.000 || acc: 1.000 || prob(true_action): 9.461E-02 || last reward: 0.614
--> iter: 55 || auroc 1.000 || acc: 1.000 || prob(true_action): 9.581E-02 || last reward: 0.334
--> iter: 56 || auroc 1.000 || acc: 1.000 || prob(true_action): 9.661E-02 || last reward: 0.620
--> iter: 57 || auroc 1.000 || acc: 1.000 || prob(true_action): 9.739E-02 || last reward: 0.043
--> iter: 58 || auroc 1.000 || acc: 1.000 || prob(true_action): 9.799E-02 || last reward: 0.213
--> iter: 59 || auroc 1.000 || acc: 1.000 || prob(true_action): 9.901E-02 || last reward: 0.532
--> iter: 60 || auroc 1.000 || acc: 1.000 || prob(true_action): 9.950E-02 || last reward: 0.468
--> iter: 61 || auroc 1.000 || acc: 1.000 || prob(true_action): 9.756E-02 || last reward: -0.022
--> iter: 62 || auroc 1.000 || acc: 0.857 || prob(true_action): 9.552E-02 || last reward: 0.437
--> iter: 63 || auroc 1.000 || acc: 0.857 || prob(true_action): 9.376E-02 || last reward: 0.339
--> iter: 64 || auroc 1.000 || acc: 0.857 || prob(true_action): 9.152E-02 || last reward: 0.487
--> iter: 65 || auroc 1.000 || acc: 0.857 || prob(true_action): 8.948E-02 || last reward: 0.349
--> iter: 66 || auroc 1.000 || acc: 0.857 || prob(true_action): 8.778E-02 || last reward: 0.379
--> iter: 67 || auroc 1.000 || acc: 0.857 || prob(true_action): 8.577E-02 || last reward: 0.598
--> iter: 68 || auroc 1.000 || acc: 0.857 || prob(true_action): 8.369E-02 || last reward: 0.164
--> iter: 69 || auroc 1.000 || acc: 0.857 || prob(true_action): 8.165E-02 || last reward: 0.174
--> iter: 70 || auroc 1.000 || acc: 0.857 || prob(true_action): 7.972E-02 || last reward: 0.215
--> iter: 71 || auroc 1.000 || acc: 0.857 || prob(true_action): 7.820E-02 || last reward: 0.356
--> iter: 72 || auroc 1.000 || acc: 0.857 || prob(true_action): 7.709E-02 || last reward: 0.590
--> iter: 73 || auroc 1.000 || acc: 0.857 || prob(true_action): 7.627E-02 || last reward: 0.581
--> iter: 74 || auroc 1.000 || acc: 0.857 || prob(true_action): 7.535E-02 || last reward: 0.568
--> iter: 75 || auroc 1.000 || acc: 0.857 || prob(true_action): 7.464E-02 || last reward: 0.558
--> iter: 76 || auroc 1.000 || acc: 0.857 || prob(true_action): 7.449E-02 || last reward: 0.515
--> iter: 77 || auroc 1.000 || acc: 0.857 || prob(true_action): 7.418E-02 || last reward: -0.028
--> iter: 78 || auroc 1.000 || acc: 0.857 || prob(true_action): 7.447E-02 || last reward: 0.564
--> iter: 79 || auroc 1.000 || acc: 0.857 || prob(true_action): 7.514E-02 || last reward: -0.003
--> iter: 80 || auroc 1.000 || acc: 0.857 || prob(true_action): 7.601E-02 || last reward: 0.536
--> iter: 81 || auroc 1.000 || acc: 0.857 || prob(true_action): 7.679E-02 || last reward: 0.448
--> iter: 82 || auroc 1.000 || acc: 0.857 || prob(true_action): 7.801E-02 || last reward: 0.562
--> iter: 83 || auroc 1.000 || acc: 0.857 || prob(true_action): 7.944E-02 || last reward: 0.545
--> iter: 84 || auroc 1.000 || acc: 0.857 || prob(true_action): 8.043E-02 || last reward: 0.615
--> iter: 85 || auroc 1.000 || acc: 0.857 || prob(true_action): 8.130E-02 || last reward: 0.449
--> iter: 86 || auroc 1.000 || acc: 0.857 || prob(true_action): 8.192E-02 || last reward: 0.380
--> iter: 87 || auroc 1.000 || acc: 0.857 || prob(true_action): 8.254E-02 || last reward: 0.390
--> iter: 88 || auroc 1.000 || acc: 0.857 || prob(true_action): 8.314E-02 || last reward: 0.575
--> iter: 89 || auroc 1.000 || acc: 0.857 || prob(true_action): 8.327E-02 || last reward: 0.539
--> iter: 90 || auroc 1.000 || acc: 0.857 || prob(true_action): 7.971E-02 || last reward: 0.175
--> iter: 91 || auroc 1.000 || acc: 0.857 || prob(true_action): 7.663E-02 || last reward: 0.516
--> iter: 92 || auroc 1.000 || acc: 0.857 || prob(true_action): 7.342E-02 || last reward: 0.562
--> iter: 93 || auroc 1.000 || acc: 0.857 || prob(true_action): 7.075E-02 || last reward: 0.398
--> iter: 94 || auroc 1.000 || acc: 0.714 || prob(true_action): 6.965E-02 || last reward: 0.632
--> iter: 95 || auroc 1.000 || acc: 0.714 || prob(true_action): 7.004E-02 || last reward: 0.177
--> iter: 96 || auroc 1.000 || acc: 0.714 || prob(true_action): 7.044E-02 || last reward: 0.570
--> iter: 97 || auroc 1.000 || acc: 0.714 || prob(true_action): 7.123E-02 || last reward: 0.207
--> iter: 98 || auroc 1.000 || acc: 0.857 || prob(true_action): 7.226E-02 || last reward: 0.528
--> iter: 99 || auroc 1.000 || acc: 0.857 || prob(true_action): 7.377E-02 || last reward: 0.607
--> iter: 100 || auroc 1.000 || acc: 0.857 || prob(true_action): 7.500E-02 || last reward: 0.521
[7]:
df = pd.DataFrame({'true_action':[(a == true_action).all() for a in hoptim.actions], 'reward':hoptim.rewards})
df = df.assign(rank=(-df['reward']).rank(method='first'))
df = df.assign(action = [x.tolist() for x in hoptim.actions])
_bins = np.linspace(min(df['reward']), max(df['reward']), 100)
plt.figure(figsize=(10,2))
plt.hist(df[lambda x: x.true_action]['reward'], color='r', alpha=0.25, label='True action', density=True, bins=_bins)
plt.hist(df[lambda x: ~x.true_action]['reward'], color='b', alpha=0.25, label='False action', density=True, bins=_bins)
plt.legend()
plt.title('Reward distribution')
plt.xlabel('Reward')
plt.ylabel('Density')
plt.yscale('log')
plt.show()
[8]:
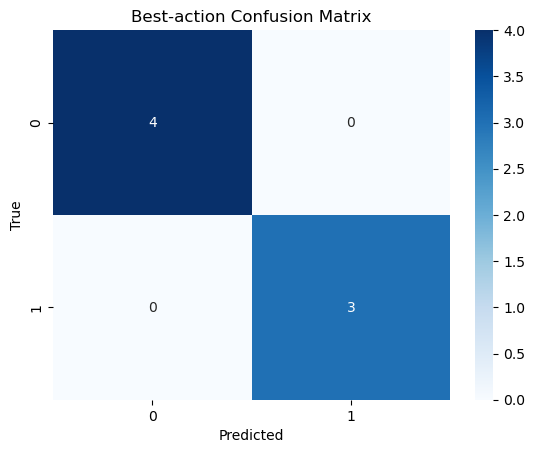
best_action = hoptim.best_action.detach().cpu().numpy().ravel()
policy = hoptim.logits.sigmoid().detach().cpu().numpy().ravel()
print('Was the true action tested/explored?', df.true_action.any())
if df.true_action.any(): print('\tRank of true action:', df[lambda x: x.true_action]['rank'].min())
print('policy', policy)
print('best_action', best_action)
print('true_action', true_action)
acc = np.mean(best_action == true_action)
auroc = roc_auc_score(true_action, policy)
print(f'best action accuracy: {acc:.3f}')
print(f'final policy auroc: {auroc:.3f}')
# plot confusion matrix
cm = confusion_matrix(true_action, best_action)
plt.figure()
sbn.heatmap(cm, annot=True, fmt='d', cmap='Blues')
plt.title('Best-action Confusion Matrix')
plt.xlabel('Predicted')
plt.ylabel('True')
plt.show()
Was the true action tested/explored? True
Rank of true action: 1.0
policy [0.959391 0.93453723 0.66035795 0.5552905 0.26664048 0.4929847
0.23389855]
best_action [1. 1. 1. 0. 0. 0. 0.]
true_action [1. 1. 1. 0. 0. 0. 0.]
best action accuracy: 1.000
final policy auroc: 1.000
[9]:
avg_reward = np.array(hoptim.rewards)
plt.figure()
plt.plot(avg_reward)
plt.plot(pd.Series(avg_reward).rolling(window=10).mean())
plt.xlabel('iteration')
plt.ylabel('average reward')
plt.show()
[ ]:
[ ]:
[ ]: